雖常流連於各大介紹好用軟體的網站與部落格,但這次算是正式第一次寫教學文,緣起是答應朋友要教他使用自己認為方便處理文書資料的程式,想想就把自己研究生生涯(??年,持續增加中...)所使用的OCR程式心得分享出來,希望能對在做研究的人一些幫助。
所謂的OCR(全稱Optical Character Recognition),正式翻譯名為「光學字元識別」,講簡單點,它是可以辨識圖像上的文字,將之轉換為電子文字訊息,即可選取、複製的文字。這對研究生來說,是引用與搜尋的絕佳利器= =+ 辨識的類別、範圍各有千秋,配合的軟硬體也有所不同,以下介紹幾款筆者常用的軟硬體及操作方法,供大家參考。
- 掃譯筆(適用數句內的小範圍辨識)
- Microsoft Office Document Imaging(限TIF圖像檔)及Microsoft OneNote(適用整頁、多頁的圖像檔)
- 尚書七號OCR(適用單、多頁,版面較為複雜的圖像檔)
- Adobe Acrobat Pro(適用於單、多頁的PDF檔,利於搜索PDF檔案的文字內容)
一、掃譯筆(適用數句內的小範圍辨識)
由蒙恬科技出品的mini掃譯筆,購買後安裝驅動程式與相應的軟體,執行程式後可選取主要辨識語言與進階設定等。這枝「筆」(?)其實就像是小型的掃描機,按壓後光所照射到的文字,會被軟體讀取後辨識。

1.
安裝好軟體後,開啟應用程式,可以從設定決定要辨識豎排或橫排文字,還有慣用左右手;辨識語言可以選擇的也很多,下圖是筆者設定的幾個可能會用到的語言,可以自由從設定中選擇更多語言。

2.
接著只要打開能夠輸入文字的介面,舉凡一般文書編輯軟體Word、記事本,甚至是搜尋引擎上的搜尋欄都可以。讓筆頭下方的按鈕按壓到紙面,以迅雷不及掩耳的速度快速刷過去......痾,其實沒這麼厲害可以辨識到,用一般速度刷過去就好,一下子辨識的字就會跑出來了~
這玩意不錯用!當然辨識率要看掃描文本清晰度、手刷過的速率而定(用一下大概就可以抓到它可辨識的速率,如果真掃不到......大概是你手殘吧)。手刷一下,文字就辨識出來了,很適合只需要掃描一頁中幾行的文字(如果要辨識好幾頁的那種,可參見下文其他軟體的介紹),豎行、橫行掃都不錯!絕對值得縮衣節食,存點錢來給它敗一枝。
PS.一般3C店都有賣,可以趁聖誕節、過年等優惠時段購入喔~
二、Microsoft Office Document Imaging(限TIF圖像檔)及Microsoft OneNote(適用整頁、多頁的圖像檔)
其實Microsoft Office就有OCR辨識軟體,在2003版本會直接附帶在「Microsoft Office工具」中(若無,請於安裝光碟中選擇「完整安裝」來重新安裝);2007的版本,可以下載SharePoint Designer 2007,透過自訂安裝設定來安裝Microsoft Office Document Imaging;至於Microsoft Office 2010之後的版本,則可以使用Microsoft OneNote來辨識。以下分別介紹兩款軟體:
1.Microsoft Office Document Imaging(適用Microsoft Office 2003-2007版本)
(1)
啟動方式為點選「開始\所有程式\ Microsoft Office\Microsoft Office 工具\ Microsoft Office Document Imaging」。
啟動方式為點選「開始\所有程式\ Microsoft Office\Microsoft Office 工具\ Microsoft Office Document Imaging」。

(2)
進入後讀取需要辨識的TIF或MDI圖像檔(注意!JPG檔無法讀取,請在掃描紙本時就要特別注意,請掃成TIF檔案)。
進入後讀取需要辨識的TIF或MDI圖像檔(注意!JPG檔無法讀取,請在掃描紙本時就要特別注意,請掃成TIF檔案)。

(3)
點選「工具\使用OCR辨識文字」。
點選「工具\使用OCR辨識文字」。

(4)
使用預設選項「所有頁面」→「確定」(第一次使用會出現安裝訊息,點「是」進行安裝)。
使用預設選項「所有頁面」→「確定」(第一次使用會出現安裝訊息,點「是」進行安裝)。

(5)
辨識完成後,點選「工具\傳送文字到Word」,之後再選擇存取路徑即可。
辨識完成後,點選「工具\傳送文字到Word」,之後再選擇存取路徑即可。

2.Microsoft OneNote(適用Microsoft Office 2010之後版本)
(1)
點選「Microsoft Office\Microsoft OneNote」。
點選「Microsoft Office\Microsoft OneNote」。

(2)
點選「插入\圖片」,選擇需要辨識的圖片檔案(沒有再限制TIF檔了,好耶~)
點選「插入\圖片」,選擇需要辨識的圖片檔案(沒有再限制TIF檔了,好耶~)

(3)
插入一頁或多頁,然後選取一頁(它一次只能辨識一頁......麻煩),對著選取圖片按滑鼠右鍵,點選「複製圖片的文字」。
插入一頁或多頁,然後選取一頁(它一次只能辨識一頁......麻煩),對著選取圖片按滑鼠右鍵,點選「複製圖片的文字」。
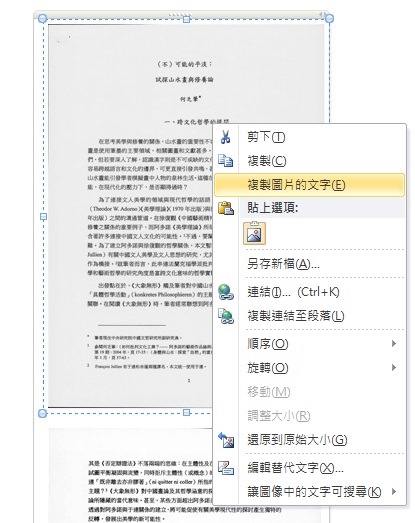
(4)
開啟Word,點選「貼上\只保留文字」,即出現辨識的文字,大功告成~
開啟Word,點選「貼上\只保留文字」,即出現辨識的文字,大功告成~

2003-2007的版本使用Microsoft Office Document Imaging,2010之後則用Microsoft OneNote。前者可多頁辨識,但限於TIF檔;後者不限格式(只要圖像檔即可),但只能一次辨識一個圖片。都有點麻煩...如果各位不想額外再安裝各種OCR軟體,這兩款在Microsoft Office內建的程式,是可以考慮的。
另外要注意的一點是,這兩款Microsoft Office的OCR程式,中文部份只能辨識繁體,拿簡體字辨識會有不少錯誤。 (不過也許對岸跟我們情況相反也說不定)
另外要注意的一點是,這兩款Microsoft Office的OCR程式,中文部份只能辨識繁體,拿簡體字辨識會有不少錯誤。 (不過也許對岸跟我們情況相反也說不定)
PS.有朋友在問為何要介紹現已不太使用的2003版本,主要是因為筆者現在主要還是在用2003啊...2003的工具列是可以自由組合的,而且該有的Word功能也不會缺少(只要你有發現...),雖然有些小細節確實2007之後比較方便些,但就整體上來說,可隨意配置工具列位置,其實還是最人性化、最便利的(至少筆者是這樣認為啦)。相信一定也有人贊同筆者的想法,所以這邊就一道介紹Microsoft Office Document Imaging了。
三、尚書七號OCR(適用單、多頁,版面較為複雜的圖像檔)
有些紙本是上下或左右雙欄式,這類在OCR程式中,有時會因雙欄間距過窄而被誤判為同一行。比方說在辨識時很容易將下圖左欄第一行與第右欄第一行連接在一起,但實際上應是左欄最後一行再接續至右欄第一行,這樣「每一行都被誤判」時,會造成很大的困擾。

而像「丹青文件管理系統」、「尚書七號」這類的OCR辨識軟體,則是可以自行修訂在一個頁面中該辨識哪些區塊,非常適合雙欄、甚至是奇奇怪怪的欄位擺置。「丹青文件管理系統」與掃譯筆同樣是蒙恬出品,價格同樣也稍微......。曾有同領域研究的教授跟筆者說,他認為「尚書七號」比較好用XD 因此以下使用「尚書七號」軟體做範例。
1.開啟程式後,讀取需要辨識的圖像(可讀取TIF、BMP、JPG圖像檔)

2.
開啟後可以看見左側是讀取檔案的清單,右側則分上下二欄,右下欄為「預覽及版面選取區」(這是亂取的...),可以看見開啟的圖像檔,以及之後在「分析版面」時可做個別版面區塊的更動(這等會兒操作會教);右上欄「辨識文字區」(同樣隨便取)則為呈顯辨識文字的區塊,可針對辨識的訛誤做編輯修正。

3.
接下來是做辨識文字所需要的設定,點選「文件\系統配置」,可以選取辨識語言,如果是繁體字,則選擇「簡繁混合」(嗯...這是對岸出的軟體嘛,但辨識度是很不錯的)。本次所欲辨識的文件,則為簡體字。

4.
再來進行版面分析,點選「識別\版面分析」。

5.
分析完後,一張圖的版面會被系統判定切割出各個區塊,每個區塊都會標號,作為文字辨識與呈現的順序,而這邊系統自動把左右雙欄區分開來了。

6.
還有一些地方被分做不同的區塊,以及最右下角不需要辨識的篇名與頁數,這些都可以手動調整。要對這些區塊做適度的調整,操作教學如下
- 增加區塊:滑鼠點擊後拖曳,可劃出一區塊。
- 刪除區塊:點選區塊後按Delete鍵刪除。
- 調整區塊範圍:滑鼠靠近區塊邊框,即可做調整。
- 修改區塊屬性:點選區塊,再點選「識別\修改欄屬性」可更改為圖像、橫欄、豎欄、表格等。辨識文字為豎行及表格時,請務必檢查。

7.
修改區塊完成後,點選「識別\開始識別」,就可以開始進行辨識。等程式跑完後,「辨識文字區」便出現文字。用滑鼠點選文字,文字上方會出現辨識的影像,這只是供參考,作用不大。不過更上方會出現所點選字的各種相似字,讓使用者點選做更正;或者,也可以直接刪除與輸入文字修改。

8.
選取及拖曳文字後,便可直接複製,再到文書編輯軟體貼上即可;或者,點選「輸出\到指定格式文件」,另存成txt檔也可以。
「丹青文件管理系統」、「尚書七號」這類的OCR辨識軟體,最大的優點在於可以辨識複雜的版面(請原諒筆者懶惰,只選雙欄式版面作示範),遇到直行、表格類的,透過區塊的適度調整,以及更改屬性,它的辨識效果可說是本文所介紹辨識軟體中最好的(尤其是直行字的識別)。缺點是要處理每個版塊,是比較費工的。
四、Adobe Acrobat Pro(適用於單、多頁的PDF檔,利於搜索PDF檔案的文字內容)
PDF檔案非常通用,尤其是電子書與自己掃瞄的紙本檔案,多半製成單一檔案,方便閱覽。有些PDF檔案是可以對上面的文字選取、複製,這類型檔案多半是由文書編輯軟體(如Word)直接轉換成PDF,文字訊息還留在上面,檔案也較小;另一種無法對文字做選取、複製的,多半是由圖像檔轉為PDF,因本來就是圖像,一開始便沒有具備文字訊息,自然無法對上頭的文字做選取和複製。
要想對後面那種PDF上面的文字做編輯,一種方式是先把DPF轉成圖像檔,然後再使用上面提到的軟體做辨識。不過這種方式有點費工,更方便的方式是使用PDF編輯軟體Adobe Acrobat Pro。它可以透過OCR辨識,讓辨識出來的文字訊息附加到PDF上相應的文字圖像上,使文字可以選取、複製,甚至還可以搜尋!
(1)操作方式非常簡單,用軟體開啟需要辨識的PDF檔案,點選「文件\OCR文字識別\使用OCR識別文字」。

(2)細部可以設定要辨識整份文件或是指定頁數,記得要依據文件整體設定辨識語言!
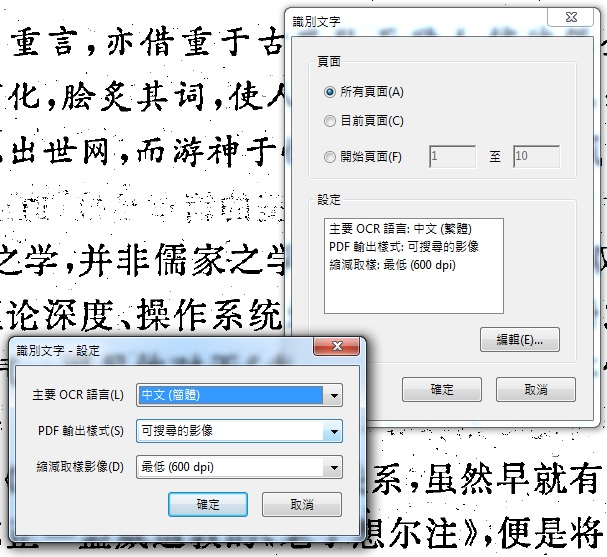
(3)接下來等程式跑完,就可以選取、複製,以及搜尋(快捷鍵ctrl+F)。不過請記得,簡體的文件,就得用簡體字搜尋喔(可用Word轉換繁簡)!
 |
若手邊有大量的PDF檔案,也可以使用「文件\OCR文字識別\使用OCR識別多個檔案中的文字」,不過請別一股腦地全丟進去,記得先分類好文件主要語言(如繁簡體),再分次給程式識別。
再者,若要把全部文字複製到Word,覺得全選複製很麻煩(其實...快捷鍵ctrl+A就可以全選了),使用OCR辨識過的PDF檔,可直接轉存成Word檔做編輯。只要點選「檔案\轉存\Word文件」,即可將整份文件轉換至Word做文字編輯。
再者,若要把全部文字複製到Word,覺得全選複製很麻煩(其實...快捷鍵ctrl+A就可以全選了),使用OCR辨識過的PDF檔,可直接轉存成Word檔做編輯。只要點選「檔案\轉存\Word文件」,即可將整份文件轉換至Word做文字編輯。

--------------------------------
以上是筆者使用OCR程式的一點小心得,不過寫得也有點瑣碎,說是「小心得」也不怎麼小啦= =||| 至於程式如何應用,端看大家的需求與使用狀況而定,有更好的軟體或者更佳的使用方式,也歡迎大家分享,希望這篇分享能讓苦海眾研究生得到點便利與幫助~最後提醒一下,OCR有效的辨識是印刷體(中文以細明體和標楷體為佳),拿手寫筆跡、書法作品、甲骨、金文、戰國文字嘗試者,絕對慘不忍睹......
至於各軟體的來源,因大部分是有版權的,不提供載點,就請大家各顯神通了~有些新式掃描機所搭配的掃描軟體,也有OCR辨識了,但辨識率好壞不一,也可以嘗試看看。
至於各軟體的來源,因大部分是有版權的,不提供載點,就請大家各顯神通了~有些新式掃描機所搭配的掃描軟體,也有OCR辨識了,但辨識率好壞不一,也可以嘗試看看。
JOCER無法使用
回覆刪除我還要處理一大堆文件QQ
還好有你這篇教學
大感謝!!
不同的OCR辨識軟體各有適用的地方,JOCER也是算便利的。現在市面上還有很多不同種類的,但我也沒特別再做更新了~感謝你不嫌棄^^
刪除剛剛在做學期論文就看完樓主這篇了XD,我看到手機上和google文件也有,但真的很爛,一堆錯字,,希望這些沒問題吧XD 感謝樓主了XD
回覆刪除